本文前半部分科普 KDF 函數的意義,后半部分探討 KDF 在前端計算的可行性。
前言
幾乎每隔一段時間,就會聽到“XX 網站被拖庫”的新聞。之后又會出現一些報道,分析該網站使用多的密碼是什么、有多少等等。
眾所周知,密碼在數據庫中通常是以 Hash 值存儲的,并且還加了鹽。攻擊者即使知道具體的 Hash 算法,也只能暴力破解。照理說這是極其費勁的,然而現實中卻總有大量密碼被破解,是什么導致安全性如此脆弱?
究其原因,莫過于這兩點:口令密碼、算法成本。
口令密碼
密碼可以記在很多地方。常見的,就是記在自己腦袋里。當然還可以記在屬于你的物品上,例如小本子、卡片等等,反正不用腦子記,不如設置的很長很亂,例如:
QQ: n5Py 2r8W qGyg 4tU6
GMail: 3TkS mVwQ hUrs wtmA
...
這種無意義的長串作密碼,是很安全的。即使它們的 Hash 值以及算法泄露,攻擊者想得到明文,只能暴力窮舉所有組合:
泄露的值是 BF656DEC5DD8BA0B,算法是 f(x)。開始窮舉...
嘗試組合 f(x) 結果
aaaa aaaa aaaa aaaa 02F49B3EA5592B14 ×
aaaa aaaa aaaa aaab BD4E960D990DA3F3 ×
...
n5Py 2r8W qGyg 4tU5 4CEA28A904326A26 ×
n5Py 2r8W qGyg 4tU6 BF656DEC5DD8BA0B √
就算只有字母和數字,也要近 10^28 次才猜到。這是個天文數字,幾乎不可行。所以,這種類型的密碼還是很安全的。
然而現實中這么做的并不多。物品需要隨身攜帶,非常不便,要是弄丟或者被偷,就更麻煩了。除非把它們都背下來,但這不又回到“記在腦袋里”這種方式了!
腦袋確實很安全,但容量也很有限。像上面那種毫無規律的字串,背一句都難,更別說多個了。所以,大家多少都會選些有意義、有規律的字串作為密碼,例如 iloveyou2016、qwert12345,或是手機號、生日等組合。這種不用死記硬背的字串,就是口令(pass word)。
口令雖然方便,但缺陷也很明顯:因為它是有規律的,所以猜起來就容易多了。攻擊者只需測試常用單詞組合,沒準就能猜到了:
泄露的值是 2B649D47C4546A3E,算法是 f(x)。開始跑字典...
嘗試組合 f(x) 結果
...
qwert yuiop 52708233CFFD6BFD ×
qwert asdfg CD07933880702B97 ×
qwert zxcvb 343F78782D73AB3A ×
qwert 12345 2B649D47C4546A3E √
這個過程,就是所謂的“跑字典”。一本好的字典,可以極大的提升猜中幾率。
算法成本
在字典相同的情況下,速度就顯得尤為重要了。每秒可以猜多少次?這得看具體的算法。
例如 MD5 函數,每次調用大約需要 1 微秒,這意味著每秒可以猜 100 萬次!(而且這還只是單線程的速度,用上多并發更是恐怖)
由此可見,算法越快,對破解者就越有利。假如每次調用需要 10 毫秒,那么每秒只能猜 100 次,這樣就足足慢了一萬倍!
然而不幸的是,常用的 Hash 函數都是很快的。因為它們生來就有多種用途,并非為口令處理而設計。例如計算一個大文件的校驗值,速度顯然很重要。所以,用 MD5、SHA256 之類的“快函數”處理口令,是不合理的。(包括一些簡單的變種,例如 MD5(SHA256(x)),仍然很快)。一旦 Hash 值和算法泄露,很容易被“跑字典”破解。
現實中,由于不少網站使用了“快函數”來處理口令,因此數據庫泄露后,大量口令被還原也就在所難免了。
增加成本
雖然 Hash 函數單次執行很快,但我們可以反復執行大量次數,這樣總體耗時就變長了。例如:
function slow_sha256(x)
for i = 0 to 100000
x = sha256(x)
end
return x
end
在密碼學中,這種方式叫做 拉伸。現實中有不少方案,例如 PBKDF2 —— 它沒有重頭設計一種新算法,而是對現有的函數進行封裝,從而更適合用于口令處理:
function pbkdf2(fn, ..., iter)
...
for i = 0 to iter
...
x = fn(x, ...)
...
end
...
return x
end
它有一個迭代參數,用于指定反復 Hash 的次數 —— 迭代次數越多,執行時間越長,破解也就越困難。
PBKDF(Password-Based Key Derivation Function,基于口令的秘鑰導出函數),顧名思義,就是輸入“口令”(有規律的字串)輸出“秘鑰”(無規律的長串)的函數,并且計算過程會消耗一定資源。本質上也是 Hash 函數,輸出結果稱之 DK(derived key)。
前端拉伸
拉伸次數越多雖然越安全,但這是以消耗服務端大量計算資源為代價的!為了能在安全和性能之間折衷,通常只選擇幾十到幾百毫秒的計算時間。
服務端的計算量如此沉重,以至于不堪重負;而如今的客戶端,系統資源卻普遍過剩。能否讓用戶來分擔一些計算量?
聽起來似乎不可行。畢竟前端意味著公開,將密碼相關的算法公開,不會產生安全問題嗎。
先來回顧下,傳統網站是如何處理口令的 —— 前端通常什么都不做,僅僅用于提交,口令都是由后端處理的:
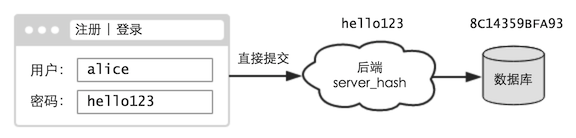
現在,我們嘗試對前端進行改造 —— 當用戶在注冊、登錄等頁面中提交時,不再發送原始口令,而是口令的 DK:
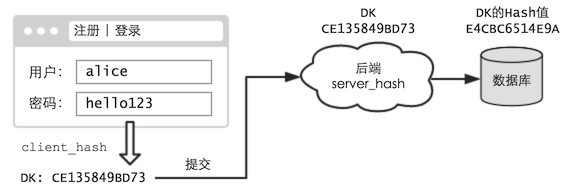
后端,則不做任何改動。(當然這會影響已有賬號的使用,這里暫時先不考慮,假設這是個新網站)
這樣,即使用戶的口令很簡單,但相應的 DK 卻仍是個毫無意義的長串。通過 DK 的 Hash 值,是極難還原出 DK 的。(在本文開頭就提到過了)
當然,攻擊者更感興趣的不是 DK,而是口令。這倒是可以破解的 —— 只需將前后端算法結合,形成一個新函數:
F(x) = server_hash(client_hash(x))
用這個終函數 F 跑字典,還是可以猜口令的。只不過其中有 client_hash 這道障礙,破解速度就大幅降低了!
JavaScript
嘗試組合 耗時 F(x) 結果
...
qwert yuiop 1s 1C525DC73898A8EF ×
qwert asdfg 1s F9C0A131F43F1969 ×
qwert zxcvb 1s 08F026D689D26746 ×
...
所以,我們需要:
一個緩慢的 client_hash,增加跑字典的成本
一個快速的 server_hash,防止 DK 泄露
這樣,就能將絕大多數的計算轉移到前端,后端只需極少的處理,即可實現一個高強度的密碼保護系統。
對抗預算
由于前端的一切都是公開的,所以 client_hash 的算法大家都知道。攻擊者可以把常用口令的 DK 提前算出來,編成一個新字典。將來拖庫后,直接跑這個“新字典”,就能節省大量時間了。
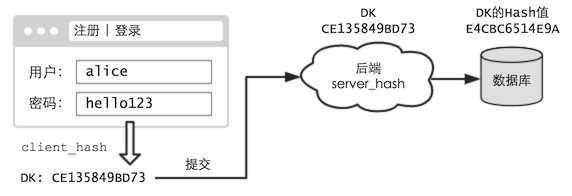
對于這種方式,就需要使用“加鹽”處理(事實上 PBKDF 本身就需要提供鹽參數)。例如,選擇用戶 ID 作為鹽:
JavaScript
function client_hash(password, salt) {
return pbkdf2(sha256, password, salt, 1000000);
}
client_hash('888888', 'tom@163.com'); // b80c97beaa7ca316...
client_hash('888888', 'jack@qq.com'); // 465e26b9d899b05f...
這樣即使口令相同,但用戶不同,生成的 DK 也是不同的。攻擊者只能針對特定賬號生成字典,適用范圍就小多了。
思考題:用戶 ID 是公開的,能不能選個隱蔽的字段作為 client_hash 的鹽?
DK 泄露
DK 誕生于前端,后端對其 Hash 之后就不復存在了,所以它是個臨時值。理想情況下,它是不會泄露的。

但在某些場合,DK 還是有可能泄露的。例如服務器中毒、網絡傳輸被竊聽等,都能導致 DK 泄露。
DK 泄露后,攻擊者就能控制該賬號了,這是無法避免的。但幸運的是,DK 只是個無意義的長串而已,攻擊者并不知道其背后的那個有意義的“口令”是什么。因此其他使用類似口令的賬號,就幸免于難了!
攻擊者若要通過 DK 還原口令,就得用 client_hash 算法跑字典 —— 這個成本依然很大。相比之前的“終函數 F”,只是少算一次 server_hash 而已。(server_hash 本來就很快,可以忽略不計)。所以即使 DK 泄露,破解口令難度基本沒降低。
“賬號被盜,口令拿不到”,這就是“前端 Hash”的意義。
撞庫成本
前端拉伸計算,使得用戶每次登陸,都會耗費一定的系統資源。這對普通用戶來說,或許影響不大;但對于頻繁登錄的人來說,將是一個極大的開銷。有誰會極其頻繁地登錄?很可能就是“撞庫攻擊者” —— 他們從其他地方弄到一堆賬號口令,然后來這里撞運氣,看看能成功登上多少。
由于我們是用 DK 登錄的,因此攻擊者也必須將待測的口令,先算出 DK 再提交,于是會增加不少計算成本。這和上一篇的 Proof-of-Work 有點類似。如同拉伸彈簧需要付出能量,拉伸 Hash 同樣需要投入實實在在的算力。
小結
本篇提到的 3 類密碼:
類型 安全性 易用性 說明
無意義的長串 高 差 很難記住,只能儲存在外部,增加了保管成本
有規律的口令 低 好 容易記住,但也容易被“跑字典”攻擊
口令轉成秘鑰 中 好 同上。但轉換過程很耗時,提高跑字典的成本
兩種 Hash 函數:
快函數(MD5、SHA256 等,輸入數據“很長很沒規律”時使用)
慢函數(PBKDF2、bcrypt 等,輸入數據“容易猜到”時使用)
關于“前端 Hash”,其實算是 “零知識證明”(zero-knowledge proof)的一種。什么是零知識證明,這里套用一個經典的例子:
你擁有一個寶庫,可以通過念咒語來開門。有天你想在朋友面前證明你能打開寶庫,但又不想讓他聽到咒語。這該如何解決?
正好,他知道你的寶庫里有個的寶物,如果能取出來給他看,自然就能證明你能打開。這樣就無需帶他到場,自己單獨打開取出寶物,然后拿給他看就行了。于是,就可以在不暴露咒語的同時,證明你能打開。
這就是零知識證明 —— 證明者在不透露“任何有用信息”的情況下,使驗證者相信某個論斷是正確的。
“前端 Hash”的做法在“密碼管理插件”中很常見:用戶的口令不再發往后端,而是僅僅用于生成 DK(并且不同賬號的 DK 不一樣,即使口令相同)。這樣就算遇到壞的情況(例如服務器中毒、傳輸竊聽、后端明文存儲等)導致 DK 泄露,也不會暴露你的口令。多損失某個賬號,而不影響其他賬號!
(另外,口令也不再填寫于原先的文本框中,而是填在插件的界面上,插件算出 DK 后自動填到原先的文本框。這樣可以降低口令泄露的風險,例如網頁中可能潛伏著惡意腳本)
實際應用
不過現實中,天生內置了前端 KDF 計算的網站并不多。不像插件可以調用本地程序,性能高且穩定,瀏覽器則是良莠不齊,不同的版本性能差異很大,因此計算時間很不穩定。
另外,在曾經很長一段時間里(IE 時代),瀏覽器的計算力都十分低下,以至于大家都保留了前端計算意義不大、“一切都由后端計算”的觀念。不過如今主流瀏覽器的性能已得到大幅提升,甚至 HTML5 還引入了 WebCrypto 規范,JS 可直接調用瀏覽器內置的密碼學算法庫,其中就包括了 PBKDF2。由于是原生實現的,因此性能非常的高。這里有個簡單的演示:
(分別使用 asm.js、Flash、WebCrypto 幾種方案,計算 100 萬次迭代的測試)
不過 PBKDF2 并不是好的,因為它只是簡單地套用了現有的 Hash 函數而已,而非針對性的進行設計。
2015 年 Password Hashing Competition 的勝出者 —— argon2,就非常了。它不僅可設置時間成本(迭代次數),還能設置空間成本(內存占用)。并且還支持多線程計算,讓攻擊者也必須投入同樣多的算力進行破解!
當然 argon2 還太新,目前尚未收錄到 WebCrypto 里。不過已有人將其移植成 JavaScrpt 版本,不妨值得一試。
深圳網站建設www.ykfic.cn
 掃碼咨詢
掃碼咨詢 掃碼咨詢
掃碼咨詢